Build Your Own Stock Market Data ETL Pipeline on AWS RDS
Pull historical data, daily updates and corporate actions into an RDS database for further calculations and analysis.
Over the last decade, the internet has delivered a huge volume of stock market data into the hands of individual investors who have basic technology skills. As we’ve seen with the rise of individual traders on Robinhood and other brokerage platforms over the last year, investing has become truly democratized. Now individual investors can even create their own personal market data warehouses on cloud-based database platforms at very little cost. In this article, I will show you how to set up a basic Extract, Transform and Load (ETL) process to pull end-of-day stock market exchange data into the Relational Database Service (RDS platform) provided by Amazon Web Services (AWS) using the Python scripting language and the MySQL database language.
The advantages of using AWS for this purpose include the ability to access the raw data from any internet-connected device, run your own custom queries and build your own custom calculations, indices and data visualizations. In this article, we will discuss how to create an initial database of historical market data with automatic daily updates.
At a high level, we will create four Python ETL scripts to feed data into two primary MySQL tables:
- An Initial data load for historical price/volume data to cover US traded equities, ADRs and ETFs
- A daily update process to keep the historical table up to date
- A daily update process for corporate actions (splits and dividends) which require ongoing adjustments to the historical data
- An initial data load and weekly update process for a security info table containing metadata for the instruments we are tracking, to be used for screening and filtering purposes to create trading strategies later on.
I’m assuming the reader has some previous experience working with Python and SQL. If you need a refresher on these languages, I recommend either Udemy or Coursera. Both sites offer excellent tutorials for free or at a minimal cost.
For this project, our primary data source will be Intrinio, a financial market data aggregator based in St Petersburg, FL. In past gigs, I have been both a supplier and customer of Intrinio and found them to be very reliable and responsive. They’re good people. I could have used the Yahoo Finance Python API for free, but I want a stable reliable source that I know will be in business for the long term and that provides support if anything doesn’t work as expected. For individual investors, Intrinio offers data packages, accessible through REST APIs, starting at $200 per month.
The tools used in this project will include Python 3.9, MySQL, AWS RDS (free tier) and AWS S3 to store the data, Jupyter Notebook to assemble the Python scripts, and MySQL Workbench or DBeaver (free edition) to run SQL statements directly. Once the scripts are created, we will use Prefect.io to set them up on automatic update schedules. All of these tools have free versions which are plenty powerful enough for this project.
Initially, we will set these processes up on a personal computer. You will need a powerful one with plenty of DRAM memory because we will be working with some large datasets, containing over 40 million rows of data. A high bandwidth internet connection is also necessary to reduce the time it takes to move this data from source to machine and then to AWS. I happen to be using a Macintosh desktop with 64 gigs of RAM which gets the job done. I have a 500 Gbps fiber optic internet connection, which is very helpful, but a regular 100 Gbps cable connection should work as well.
There are about a dozen Python libraries that I use to accomplish the various tasks in this process. All of them are free, or have free versions available. Some simply require a Python import statement in your Jupyter Notebook. A few require installation, usually with PIP (“pip install <library name>” in Jupyter). I have posted a list of them, along with links to documentation and installation instructions, in a text file on my Github account.
So now, on with the show. The first order of business is to set up your Amazon Web Services account and your own RDS instance and S3 bucket. Instead of going through that process in detail here, I’m going to refer you to a few Youtube videos:
First, for security purposes, we want to create a credentials file in a secure place on your hard drive that contains all your passwords and API keys. There are many ways to do this, but I think the easiest way is to create a CSV or JSON file. Here’s an example of a credentials file I created in JSON, which is really just a dictionary of key:value pairs saved as a *.json file.
You will open this file at the beginning of each Python script using a json.load command, then map it to variables as shown here:
Next, we want to create the Python scripts that will run the ETL process. I’m going to describe these scripts in general terms here, with a few sample code snippets. The full code files are available in my Github repository here:
The first script we want to create would pull historical end-of-day market data for US stocks, ETFs and ADRs from Intrinio, clean it up a bit, assemble it into a Python DataFrame, archive it on AWS S3, then push it into an RDS MySQL table.
Price History Table
The modules are set up to execute the following steps:
Import credentials and libraries — code is shown above.
Download and assemble the Intrinio bulk market data files — For bulk historical data downloads, Intrinio provides a set of zipped CSV files accessible from a JSON dictionary list containing URL links to the files. Since this script only needs to be run one time, you can either download the files manually from your Intrinio dashboard and pull them into a Pandas DataFrame using the pd.read.csv command, or you can use the Python urllib.request library to download them directly into a DataFrame. I have included modules for both methods in the Jupyter file on Github.
Get shares out data and calculate market caps — In the bulk files, Intrinio provides daily open, high, low, close prices and volume figures, both original and adjusted, along with a few calculated items like 52-week hi/lo figures. However, they don’t provide shares outstanding figures in those files. We want shares outstanding so we can calculate market cap figures to be used in trading strategy filtering later on. For that data, we need to use an iteration script to query the Intrinio REST API one instrument at a time.
There are two ways to do this kind of iteration. You can use a regular Python For Loop which will take a couple of hours to go through thousands of instruments, or you can use the Concurrent Futures tool (ThreadPoolExecutor) for Python, which will distribute the work over several “worker’ processors, hitting the API several times at once and cutting the query time by about one third.
One caveat however, some data vendors impose rate limits on their APIs, which will limit the number of times that you can query them per second, minute, hour, etc. If that happens, you can either negotiate an upgrade to the rate limit, or install a small “sleep” function (“time.sleep(<decimal fraction of second>)”) in your code to stay under the rate limit. It just means that your script might take a little longer to finish.
For mapping the right data to the right instrument, I found it more reliable to use the Bloomberg Financial Instrument Global Identifier (FIGI) codes rather than trading symbols or “tickers”. As stocks get delisted and relisted, their tickers can be reused over time, which causes no end of grief for market data archivers. FIGI codes are uniquely mapped to each company and each of its trading instruments, they are never reused, and they are available to use free of charge. Intrinio maintains FIGI codes for each instrument they track in their data system.
Transform the data to add more fields and get it to line up on a daily observation frequency — Next, we need to merge the shares outstanding data with the exchange DataFrame, then add a key ID column and several date columns to track updates and corporate actions. You’ll also notice that the shares outstanding data is reported quarterly, so we need to resample that data to convert it to a daily observation frequency. And just in case we accidentally generate some duplicate rows, we need to dedupe the data.
Archive the data to S3 in zipped CSV and Parquet files — Once the final historical DataFrame is created and transformed into the proper format, we want to save a copy of it to our S3 bucket. I like to save it in both compressed CSV and parquet formats. S3 storage space is cheap, so why not? That way, you always have a clean copy if something goes awry.
AWS provides a library, Boto3, that facilitates moving files in and out of their S3 storage system. Amazon’s Boto documentation is extensive, but hard to follow. For a quick start tutorial, I found this site, RealPython.com to be more helpful.
For those who don’t know about the parquet file format, it is designed to feed into “column-oriented” databases such as Amazon’s Redshift database. Column-oriented databases like Redshift are designed to handle very large datasets, consisting of many columns and billions of rows. Without going into all the details, the primary advantage of these databases is that they allow you to run queries much faster, which is facilitates more advanced machine learning algorithms. So down the road, if you want to start running complicated algorithms against this data, saving it in a parquet format will allow you to easily import it into Redshift or other “Big Data” platforms for more creative analyses. Here’s a notebook that you might want to check out to compare the performance of the most popular file storage formats — CSV, parquet and HDF5.
Create the price history table in RDS and upload the data — Once the DataFrame is ready, and a copy is saved to S3, you want to go ahead and upload it to the RDS price history table. Once again, there are several ways to accomplish this task.
Since you may only need to do this one time, you could just save the price history data to a large CSV file and use a couple of SQL statements to create the table and upload the data manually. These commands would do the trick in MySQL Workbench or DBeaver:
Create the Price History table:
Load the data:
If you have a fat fiber optic internet pipe like I do, this operation could take as little as 20 minutes. Or if you have a more typical cable pipe with slower upload speeds, it could take several hours. In total, you’d be loading about 12 Gb of data.
Once the data is loaded, you want to index several of the fields that you will probably be using in queries more often. I suggest that you index the ticker, figi, date, last_update_date, last_corporate_action_date, and key_id fields. Indexing will dramatically speed up queries that filter results using these data fields. The key_id field is a concatenated combination of date, ticker and FIGI code. You could use these SQL commands to create the indexes:
Index the fields:
Finally, I suggest you also create a full backup price history table, again just in case something gets screwed up and you need a clean version. These SQL commands would do that trick:
Create backup table:
Now once you’re done with this table, I would suggest you run this process and replace the price history table entirely about once a quarter. Daily updates are great and pretty reliable, but Murphy’s Law says some details will be missed. In that case, you might want to run the whole thing from a Python script and not rely on manual SQL commands. For that purpose, I included a module in the Notebook that uses the SQL Alchemy library to execute the SQL commands above straight from the Jupyter Notebook interface. It is slower, but more automated.
Again, that Notebook is located at
The next step is to create two scripts, one to update the market data for each new trading day and the other to adjust the data for stock splits and dividends.
Unlike other kinds of data, historical stock prices must constantly be readjusted each time a company issues a stock split or pays a dividend. Otherwise, if you plot the historical data on a time-series graph, you will see sudden ups and downs in the chart that do not reflect actual price movements.
Here’s an example of what unadjusted data can look like if you don’t adjust it for splits and dividends:
The red line in the chart above is the historical unadjusted stock price for AAPL from Jan 2019 forward. The yellow line is the adjusted stock closing price. As we know, AAPL executed a stock split on 4 to 1 stock split on Aug 28, 2020. The unadjusted price went from about $500 per share to about $125 per share in one day. But we know that AAPL’s stock did not lose 75% of its value that day. All the company did was increase the nominal shares outstanding while lowering the price per share proportionately. The market cap (total value) for the stock stayed the same. But if we did not back-adjust our historical share price records for AAPL accordingly, we would see a big drop in the share price on Aug 28 which never actually happened.
Stock Price Updates
The modules in this script are set up to execute the following steps:
Get the last trading date from the history table — This module uses the MySQL Connector library to query the historical price data table we just created to find the last date value in the date column and calculate the number of days passed since the last update.
Get the stock price EOD data for USCOMP exchanges for each trading day since the last date — For each day that has passed without an update, we need to query the Intrinio API to fetch the price/volume data for that day for each actively traded instrument (equity, ETF or ADR). Fortunately, Intrinio provides a bulk API endpoint that will fetch recent data for all major US exchanges in one query.
The max number of records pulled per query is 10,000, and this endpoint will actually return 20K+ records. So I have written the code with a While Loop to run multiple queries using the next_page parameter if needed (“ while next_page != None:”), just to make sure we get all the data that we actually want. Then we filter the returned records to just the equity, ETF and ADR instruments we actually want.
Get shares out data — Next, we grab the most recent shares outstanding data for each equity and ADR instrument as described above. The shares outstanding data actually comes from the cover sheet of quarterly financial reports that each company files with the SEC. I found that there are occasionally some “fat-finger” errors contained in those reports, such as zeros or negative shares outstanding figures, so I included a couple of commands in the code to correct for those errors.
Intrinio does a pretty good job of filtering a lot of that crap out, but no data vendor is perfect. ;-) Remember, capital markets data is inherently messy, and there is no data vendor who does a perfect job of cleaning it up. So you will need to be prepared to code workarounds on your side when you find data errors from time to time.
Join DataFrames, calculate market caps, 52 week hi/lo and other fields — Once we have all the data, we join it up to a completed DataFrame, calculate the market cap figures, add both a last_update_date and last_corporate_action_date column, then sort by ticker and date ascending.
Archive the data to S3 in CSV files — As we did with the full price history DataFrame above, I like to archive each day’s update file to an S3 bucket in CSV format using the AWS Boto library. That way, if something goes wrong and we have to redo the updates again, we have ready transformed files to pull from. Again, S3 storage is cheap, so it doesn’t hurt to save data there just in case.
Push the data to the RDS price history table — At the end of this process, we append the new data to the existing price history table in RDS using the SQL Alchemy library.
The full code is in a Jupyter Notebook in my Github repository at
So as of this writing, I ran the Stock Price Update script yesterday, 12/05/2021. Here are the results:
Note that I waited nine days between updates, and four of those were weekend days. So the updated data covered five trading days. With about 8,000+ active tickers, the total number of new rows added should be more than 40,000. In fact, the actual number of new rows is 42,774 as shown in the Jupyter Notebook screenshot above. So let’s check to see if that number is reflected in the database by running the following SQL commands in our MySQL IDE:
Once the price history data is updated, we need to find out which instruments have issued stock splits or dividends since the last corporate actions update and grab the newly adjusted price history data for those instruments.
Corporate Actions Updates — The modules in this script are set up to execute the following steps:
Get the last corp actions date from the history table — This is the same step as described in the price data update section above, except that here, we key on the last_corp_action_date field instead of the last trading date. This will tell us how many days have passed since the last corporate actions update, which we will use in a For Loop to find the adjusted instruments for each day.
Get the tickers/FIGIs for all securities that were adjusted since the last date — For each day since the last corporate actions adjustment date, we will query the Intrinio API to pull the tickers and FIGI codes for every instrument that has done a stock split or paid a dividend. If there are no adjustments for the date range, the module will indicate that and quit. However, one should expect to see roughly 30 to 50 adjusted instruments per day at any given time.
Get new adjustment factors and splits — Once we get the list of adjusted instruments, we will need to query our updated price history table to get the historical adjustment factors and split ratios for each instrument.
By the way, each time we run a query to fetch data for a list of instruments, we are using the FIGI codes as the primary identifier, not the trading tickers, as mentioned earlier. Trading symbols are not always unique to each instrument, whereas FIGI codes are unique.
Get new adjusted historical prices — For each adjusted instrument, we need to grab the new historical adjusted data. Since we need to query the Intrinio API one FIGI at a time, we again use the Concurrent Futures library to speed that process up as much as possible by using multiple threads to pull the data.
Get shares out data — Same process as described above, using Concurrent Futures.
Combine and transform the adjusted data — Once we have all the historical data for the adjusted instruments, we merge the DataFrames, calculate market caps, add date columns including setting the last_corp_action_date field to today’s date, and make sure the data types are SQL friendly.
Archive new data to S3 — As before, we archive the new data to an S3 bucket in case we need to re-insert it later on.
Grab old adjusted data and save it to S3 in case of screw up — Now since we are replacing existing records in the price history table, first we query that table to grab the old data for the adjusted instruments, and save it to an S3 bucket to re-insert into the table in the event that our next module fails and the data becomes corrupted for some reason. That would be highly unlikely, but it never hurts to be safe.
Since the list of adjusted instruments can be kind of large, the dataset returned by this query can be larger than allowed by the maximum number of rows permitted in the AWS Free Tier pricing level, I included a For Loop that breaks the query up into smaller chunks to avoid a query time-out problem.
Delete old data and insert newly adjusted data to history file — Since MySQL does not provide an “UPSERT” command, which will replace existing data and add new data in one operation, we need to replace the old adjusted data in two steps.
First, delete the old data, which we have already saved separately in an S3 bucket. Second, insert the newly adjusted data into the price history table. We can use the PyMySQL library for this job since it seems to handle larger data loads a little better than the SQL Connector library does.
The last step in this project is to create and update what I call a Security Information table. It will contain metadata for all the stocks, ADRs and ETFs that we want to track, including which ones are actively traded or delisted and the sectors and industries that each company belongs to. We will want to use this information for sorting and screening as we create investing strategies from this data later on.
Before you start on the Python script, you want to create the Security Info table in RDS with the columns already defined. You can do that by running this SQL command in MySQL Workbench or DBeaver:
Create the Security Info table:
You actually want to run this SQL command twice, to create two tables — security_info and security_info_old. I’ll explain why below.
Security Info Table
The modules in this Python script are set up to execute the following steps:
Get the list of currently active tickers/FGIs — To start with, we query the Intrinio Get All Securities endpoint to fetch a list of all current actively traded securities on US major exchanges. We will query it three times for equities, ETFs and ADRs respectively. That way, we filter out all the other stuff we don’t need, like bonds, warrants, preferred stocks, etc.
Get metadata for equity and ADR tickers — Intrinio has another bulk download endpoint for company metadata, which we will query next. This includes items like company business descriptions, address, website, CEO name, CIK & SIC codes, first/last recorded stock price and other items we might want to use for screening later on.
Get sector and industry mapping from FinViz — This module uses a free API provided by FinViz.com to provide a variety of stock data points. I use it here to grab their sector and industry classifications, which cover about 5,300 US stocks and are very useful for generating sector rotation trading strategies. This endpoint grabs data one ticker at a time, so again, we use the Concurrent Futures library to shorten the process.
Combine metadata and sector/industry data with active ticker lists — This is where we combine all the separate data sets into one Pandas DataFrame, then add the key_id and update date fields and remove any duplicates.
Archive new data to S3 — As in the other procedures described above, we push a CSV copy of the new data to an S3 bucket for later use if we need it.
Copy the old data to a backup table — As we did with the corporate actions data above, we want to copy the old security info to a separate backup table, security_info_old. This will be used in the unlikely event that the update job fails and we need to recreate the most recent version of the table.
Compare new and old data to identify dead securities, join dead tickers to new data — This module compares the new security info data, by ticker, to the previous data and flags any tickers that are no longer trading.
This is the one instance where we key on ticker rather than FIGI code. The objective is to maintain a Security Info table where each record is flagged as active_status = 0 for dead or 1 for active. At any given time, we want the trading tickers to be unique to each actively traded security since that’s what we will be searching for in trading indicators we develop later on.
We still want to keep data for the newly deceased tickers though because we will want to use that data in strategy back-testing routines to minimize look-ahead bias. So we will set the active_status column to 0 for the dead tickers and add them back to the active ticker data before we update the table.
Also in this module, we make sure all the date columns are properly set to the DateTime data type to be SQL friendly on the upload. In fact, all date fields need to be set to the DateTime format to be SQL friendly.
Replace the old data with new data in RDS — Finally, we use the SQL Alchemy library to replace the old security info data with the new data, or load the table if we are creating it for the first time.
I recommend running this Securities Info routine once a week to capture new IPOs and flag dead tickers on a regular basis.
We have now created our ETL processes to harvest stock market data from Intrinio to our very own stock market data warehouse in the AWS cloud. But we’re not quite done yet. We still need to automate the update processes from start to finish.
For that job, we will use a new data pipeline automation application called Prefect. Prefect works well with Python and offers a free tier for small jobs like this one. Prefect works by analyzing the deliverables generated by each Python function in our scripts and the dependencies between them. Then it creates what’s called a Directed Acyclic Graph (DAG) model which determines the order in which our modules need to be executed. Then Prefect adds a flexible scheduling service that lets us determine when and how often each process should run. I won’t get deep into the Prefect instructions here, and would instead encourage you to browse through Prefect’s tutorial docs when you get a chance.
With Prefect, the key is to think about what variables and objects are passed from one function to the next in the scripts. Then make sure those items are included in the “return” statement at the end of the function where they are created, and in the parentheses part of the function declaration statements where they are going to be used. Also, it is a good idea to declare all variables and objects as “global” in the functions where they are created. That makes troubleshooting easier if/when errors might pop up.
For example in this function, the df_price_update_total DataFrame is passed in from the previous function, a new DataFrame, df_shares_out, is created and returned for use in the next function. In addition, both the new DataFrame and an interim NumPy array, shares_out_lists_combined, are declared as global variables.
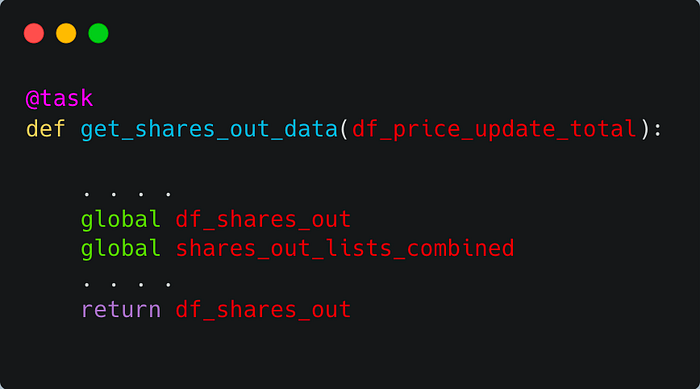
Prefect should then recognize the objects passed into and returned by each function to determine the workflow task order. But just to make sure, you can directly control the task order by inserting “upstream_tasks = [<preceding task>] “ and specifying each task dependency in this parameter. For an example of how to do this, see the Triggers section of the Prefect docs.
If the Prefect jobs run successfully, you should see results that look like these Jupyter Notebook screenshots:
Stock Price Update:
Corporate Actions Update:
In my Github repository at
I have provided versions of the full Python codes for each process, both with and without the Prefect implementation.
Now that we have our stock market database created and updated regularly, we are in a good position to generate new calculations, reports, analyses and trading strategies as we spot new trends and opportunities. That will be the focus of my next few articles.
In the meantime, I’m available for consulting assignments if your company could use help with this kind of ETL project. Feel free to reach out to me through LinkedIn at https://www.linkedin.com/in/bryantsheehy/.
Happy Trading!
Bryant Sheehy has 15+ years of experience in financial data sales and business development, and is now transitioning to data engineering and analytics. You can follow him on Medium or contact him on LinkedIn.
The opinions expressed here do not constitute investment advice. If you intend to use these ideas to make your own investments, please seek the advice of a licensed professional advisor.
